Vom Workshop bis zum Go‑Live: wie man Prozesse auswählt, die KI wirklich verbessert


KI kann spektakuläre Effekte bringen… aber nur dann, wenn sie auf den richtigen Prozess trifft und die Rahmenbedingungen hat (Daten, Tools, Owner, KPIs, Risikokontrolle). Andernfalls endet es bei einem „schönen Demo“ und Enttäuschung, weil wir etwas automatisieren, das:
- selten und nicht standardisiert ist,
- ein zu hohes Fehlerrisiko hat,
- keine messbare Wirkung hat,
- Daten erfordert, die das Unternehmen nicht hat oder nicht nutzen darf.
Dieser Leitfaden zeigt einen praxisnahen Pfad: Workshop → Selektion → Pilot → produktives Go‑Live. So, dass KI die Durchlaufzeit wirklich verkürzt, Kosten senkt und Qualität verbessert – und nicht nur „beeindruckt“.
Warum die Prozessauswahl entscheidend ist (und wo meist das größte Potenzial steckt)
Studien von McKinsey zeigen, dass der größte Teil des Wertes generativer KI sich in Bereichen wie Customer Operations, Marketing & Sales, Software Engineering und F&E konzentriert.
Das ist ein guter Hinweis, wo man nach „KI‑freundlichen“ Prozessen suchen sollte, aber man muss trotzdem eine Ebene tiefer gehen: von Funktionen (z. B. „Kundenservice“) zu konkreten Workflows und Aufgaben (z. B. „Ticket‑Triage + Antwortvorschläge + CRM‑Aktualisierung“).
Schritt 0: zuerst klären, welche Art von Verbesserung Sie erreichen wollen
In der Praxis lassen sich KI‑Einführungen in drei Kategorien einteilen (und jede braucht andere Prozesse):
- Copilot / Assistenz – KI unterstützt Menschen (erstellt Entwürfe, Zusammenfassungen, Antwortvorschläge).
- Automatisierung (End‑to‑End oder teilweise) – KI führt Prozessschritte selbstständig aus, oft mit Human‑in‑the‑Loop‑Kontrolle.
- Entscheidungen / Vorhersagen – KI empfiehlt eine Entscheidung (z. B. Priorität, Risiko, Routing), „schließt“ den Prozess aber in der Regel nicht eigenständig.
Der sicherste Einstieg ist meist Assistenz + Teilautomatisierung, weil sie schneller Wert liefern und einfacher zu steuern sind.
Schritt 1: ein Prozess‑Discovery‑Workshop, der nicht mit einer „Wunschliste“ endet
Ein guter Workshop endet mit einer Landkarte von Kandidaten + Bewertungsdaten und nicht nur mit einem „Brainstorming“.
Teilnehmende: Prozesseigentümer, operative Person (führt die Aufgaben aus), IT/DevOps‑Vertreter (Integrationen), Security/Datenschutz‑Spezialist (z. B. DSGVO, Daten) sowie eine für Kennzahlen und Analytics verantwortliche Person (Finanzen/Analytics).
Ergebnisse des Workshops:
- 10–30 Kandidaten (Prozesse oder Teilprozesse),
- für jeden: Ziel, Inputs/Outputs, Systeme, Volumen, Varianten, Fehler, Risiken, „Engpässe“.
Wie man schnell die Wahrheit über einen Prozess sammelt (statt Meinungen)
Wenn möglich, stützen Sie das Discovery auf Daten:
- Process Mining (Ereignislogs aus Systemen) und Task Mining (was Menschen tatsächlich am Desktop klicken) zeigen den tatsächlichen Prozessverlauf und wo Fehler, Verzögerungen und Automatisierungspotenziale liegen. Microsoft beschreibt dies als eine Art „Röntgenaufnahme“ des Prozesses zur Identifikation von Automatisierungschancen.
- Process‑Mining‑Tools (z. B. aus dem RPA‑Ökosystem) betonen, dass dies eine Alternative zu „Interviews und Meetings“ ist, die oft ein unvollständiges Bild liefern.
Schritt 2: Prozessselektion – ein Scoring, das in der Praxis funktioniert
Statt zu diskutieren „welcher Prozess ist cool“, nutzen Sie ein einfaches 1‑bis‑5‑Scoring in zentralen Dimensionen. Danach wählen Sie die 2–3 besten für ein Pilotenprogramm aus.
A. Geschäftswert (Impact)
Bewerten Sie:
- wie viele Stunden pro Monat der Prozess frisst,
- wie viel Fehler kosten (Rework, Reklamationen, Verluste),
- ob er sich auf Umsatz auswirkt (Conversion, Churn),
- ob er Skalierung ermöglicht (mehr Kunden ohne zusätzliche Hires).
Hinweis: McKinsey hebt hervor, dass ein „Use Case“ ein messbares Ergebnis haben sollte (z. B. Kostenreduktion, Umsatzsteigerung).
B. Wiederholbarkeit und Standardisierung
KI verbessert am besten Prozessfragmente, die:
- häufig vorkommen,
- einem ähnlichen Muster folgen,
- klare Rahmenregeln haben (wann eskalieren).
C. Daten und Zugriff (Data Readiness)
Prüfen Sie:
- ob Daten existieren (Ticketing/CRM/ERP/Logs),
- ob sie qualitativ ausreichen (konsistente Felder, wenig unstrukturierter „Freitext“),
- ob sie rechtlich und sicher nutzbar sind.
D. Integrationen und Umsetzbarkeit (Feasibility)
Hilfsfragen zur Einschätzung der „Einführungs‑Schwierigkeit“:
- Wie viele Systeme müssen integriert werden (und wie stark sind sie voneinander abhängig)?
- Gibt es APIs oder andere Integrationspunkte, oder braucht es überall Workarounds?
- Lässt sich „am Rand“ starten – z. B. im Assistenzmodus, Shadow Mode oder als paralleler Prozess, bevor man in den „Hauptstrom“ der Operation geht?
E. Risiko und Kontrolle (Risk)
Hier spielen Security, Compliance und Reputation hinein. „Shadow AI“ (Nutzung von KI‑Tools ohne Aufsicht) ist ein reales Problem – Gartner prognostiziert, dass bis 2030 über 40% der Organisationen Sicherheits‑ oder Compliance‑Incidents aus diesem Grund erleben werden. Daher sind Policies und Schulung entscheidend.
Ein einfacher Weg zur Kandidatenwahl: Zuerst auf Prozesse mit hohem Impact und hoher Feasibility, aber niedrigem Risk zielen – diese sollten als erste in den Piloten gehen.
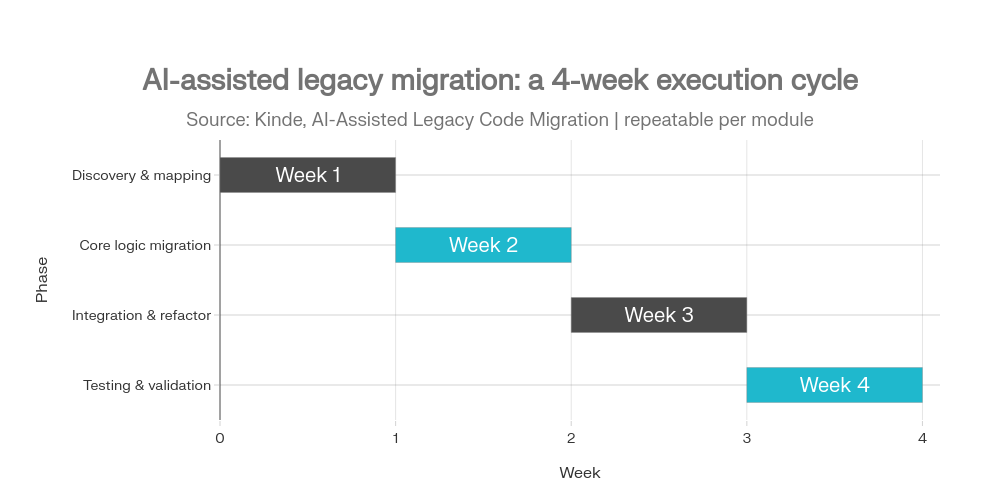
Schritt 3: „Thin Slice“ definieren – minimale Einführung, die KPIs liefert
Der häufigste Fehler: zu versuchen, den gesamten Prozess auf einmal zu verbessern.
Besseres Muster:
- einen Prozessschritt auswählen (z. B. „Ticket‑Triage“),
- 1–2 KPIs festlegen (z. B. Zeit bis zur ersten Antwort, % korrekter Routings),
- eine Lösung bauen, die in 2–6 Wochen einen Trend zeigt.
OpenAI betont in seinem Leitfaden zur Identifikation und Skalierung von Use Cases, dass KI‑Adoption mehr ist als die Ideensuche – man braucht einen Prozess, der von Wert und Leadership‑Buy‑in bis zu Umsetzung und Skalierung führt.
Schritt 4: Qualitätskontrolle und „Sicherungen“ von Tag eins an gestalten
Wenn KI Einfluss auf Kunden, Finanzen oder Sicherheit haben soll, legen Sie klare Regeln fest: wer die Nutzung freigibt, welche Daten verarbeitet werden dürfen, welche Qualitätskontrollen gelten und welche Risikokennzahlen Sie überwachen.
- Human‑in‑the‑Loop (Mensch gibt frei),
- Konfidenzschwellen (unter Schwelle → Eskalation),
- Qualitätsmonitoring (z. B. Stichprobe von 50 Fällen pro Woche),
- Protokollierung von Entscheidungen (Auditierbarkeit),
- Datenpolicy (was darf ins Modell / was nicht).
Das begrenzt auch das Risiko von „Shadow AI“, weil es Menschen einen legalen, sicheren Nutzungsweg bietet.
Schritt 5: erst dann „skalieren“ – Muster standardisieren und replizieren
Skalierung bedeutet nicht, „weitere Prompts hinzuzufügen“. Es geht um:
- einen Standard für Integrationen,
- eine Komponentenbibliothek (z. B. Klassifikation, Extraktion, Generierung, Validierung),
- gemeinsame KPIs,
- einen Prozess für Änderungseinführung und Tests.
Eine gute Praxis ist ein Discovery‑Prozess auf Basis von Mining: Process Mining zeigt, wie der Prozess tatsächlich durch Systeme fließt und wo Verluste entstehen (Engpässe, überflüssige Schritte), Task Mining zeigt, wie Menschen die Arbeit am Desktop ausführen und welche Tätigkeiten sich zur Automatisierung eignen.
Beispiele für Prozesse, die KI „wirklich“ verbessert
Nachfolgend Inspirationen, die im Scoring oft gut abschneiden:
Kundenservice / Helpdesk
- Klassifikation und Routing von Tickets,
- Kontextzusammenfassung aus der Kundenhistorie,
- Antwortvorschläge + Links zur Wissensdatenbank,
- Erkennung von Eskalationen/Churn‑Risiko.
Vertrieb und Marketing
- personalisierte E‑Mail‑/Angebotsentwürfe,
- Gesprächszusammenfassungen und CRM‑Pflege,
- Lead‑Qualifizierung (Assistenz, kein „Autopilot“).
Software Engineering
- Generierung von Tests, Dokumentation, assistiertes Refactoring,
- Bug‑Triage, Incident‑Zusammenfassungen.
Das korreliert mit den Bereichen höchsten Wertes, die in der McKinsey‑Analyse genannt werden.
FAQ: wie man Prozesse auswählt, die KI wirklich verbessert
Woran erkennt man, dass sich ein Prozess (noch) nicht für KI eignet?
Wenn er geringes Volumen hat, hohe Datenunordnung, keinen KPI‑Owner oder sehr hohes Fehlerrisiko ohne Kontrollmöglichkeit – besser anderswo starten oder zuerst die Daten aufräumen.
Sollte KI den Prozess sofort End‑to‑End automatisieren?
Selten. Meist ist ein Einstieg über Assistenz oder Teilautomatisierung mit menschlicher Freigabe sinnvoller, und erst danach wird die Autonomie erhöht, wenn Qualitätsdaten vorliegen.
Welche Daten sind minimal für einen sinnvollen Piloten nötig?
Es reicht, genug Daten zu haben, um KPIs zu messen und die Lösung zu trainieren/kalibrieren: Prozesslogs, historische Tickets, Fallbeschreibungen, Ergebnisse (z. B. ob Routing korrekt war). Process Mining / Task Mining können helfen, die „Wahrheit“ über den Prozess aus Logs und Benutzeraktionen zu ziehen.
Wie vermeidet man „Shadow AI“ und Datenabfluss in Tools?
Geben Sie Teams eine sichere Alternative (freigegebene Tools, Datenregeln, Monitoring) statt nur eines Verbots. Gartner warnt, dass nicht autorisierte KI‑Nutzung zu Sicherheits‑ und Compliance‑Verstößen führen kann.
Wie lange sollte ein Pilot dauern, damit er Sinn ergibt?
Meist 2–6 Wochen für einen „Thin Slice“. Wichtiger als die Dauer ist, ob Sie KPIs, einen Owner, Datenzugriff und die Möglichkeit haben, auf einem realen Arbeitsausschnitt zu deployen.
Ist Process Mining zwingend notwendig?
Nicht immer, aber es hilft stark, entscheidungen auf Basis von Meinungen zu vermeiden. Wenn Sie Logs in Systemen (CRM/ERP/Ticketing) haben, zeigt Process Mining Engpässe und Prozessvarianten schneller.
Welche KPIs zeigen am häufigsten den realen Wert von KI?
Durchlaufzeit (Cycle Time), Zeit bis zur ersten Antwort, Kosten pro Fall, % Fehler/Rework, Kundenzufriedenheit, Team‑Throughput ohne Personalaufstockung.