Od warsztatu do wdrożenia: jak wybierać procesy, które AI naprawdę usprawni


AI potrafi dać spektakularne efekty… ale tylko wtedy, gdy trafia w właściwy proces i ma warunki do działania (dane, narzędzia, właściciela, KPI, kontrolę ryzyka). W przeciwnym razie kończy się na „ładnym demie” i rozczarowaniu, bo automatyzujemy coś, co:
- jest rzadkie i niestandardowe,
- ma zbyt duże ryzyko błędu,
- nie ma mierzalnego wpływu,
- wymaga danych, których firma nie ma lub nie może użyć.
Ten przewodnik pokazuje praktyczną ścieżkę: warsztat → selekcja → pilot → produktowe wdrożenie. Tak, żeby AI realnie skracało czas, zmniejszało koszty i poprawiało jakość - a nie tylko „robiło wrażenie”.
Dlaczego selekcja procesów jest kluczowa (i gdzie zwykle jest największy potencjał)
Badania McKinsey wskazują, że największa część wartości generatywnej AI koncentruje się w obszarach takich jak customer operations, marketing & sales, software engineering oraz R&D.
To dobra podpowiedź, gdzie szukać procesów „AI-friendly”, ale nadal trzeba zejść poziom niżej: z funkcji (np. „obsługa klienta”) do konkretnych strumieni pracy i zadań (np. „triage zgłoszeń + sugerowanie odpowiedzi + aktualizacja CRM”).
Krok 0: najpierw ustal, jaki typ usprawnienia chcesz osiągnąć
W praktyce wdrożenia AI dzielą się na trzy kategorie (i każda wymaga innych procesów):
- Copilot / asysta – AI wspiera człowieka (tworzy szkice, podsumowania, propozycje odpowiedzi).
- Automatyzacja (end-to-end lub częściowa) – AI wykonuje kroki procesu samodzielnie, często z kontrolą człowieka (human-in-the-loop).
- Decyzje / predykcje – AI rekomenduje decyzję (np. priorytet, ryzyko, routing), ale zwykle nie „zamyka” procesu sama.
Najbezpieczniejszy start to zwykle asysta + półautomaty, bo szybciej dają wartość i łatwiej nimi zarządzać.
Krok 1: warsztat odkrywania procesów, który nie kończy się listą „życzeń”
Dobry warsztat kończy się mapą kandydatów + danymi do oceny, a nie „burzą mózgów”.
Uczestnicy: właściciel procesu, osoba operacyjna (realizująca zadania), przedstawiciel IT/DevOps (integracje), specjalista ds. bezpieczeństwa/RODO (dane), osoba odpowiedzialna za mierniki i analitykę (finanse/analityka).
Efekty warsztatu:
- 10–30 kandydatów (procesy lub podprocesy),
- dla każdego: cel, wejścia/wyjścia, systemy, wolumen, warianty, błędy, ryzyka, „wąskie gardła”.
Jak szybko zebrać prawdę o procesie (zamiast opinii)
Jeśli możesz, oprzyj discovery na danych:
- process mining (logi zdarzeń z systemów) i task mining (co ludzie realnie klikają na desktopie) pokazują faktyczny przebieg procesu i miejsca, gdzie są błędy, opóźnienia i potencjał automatyzacji. Microsoft opisuje to jako sposób na „prześwietlenie” procesu i identyfikację okazji do automatyzacji.
- narzędzia process mining (np. ekosystem RPA) podkreślają, że to alternatywa dla „wywiadów i spotkań”, które często dają niepełny obraz.
Krok 2: selekcja procesów – scoring, który działa w realnym świecie
Zamiast dyskutować „który proces jest fajny”, zastosuj prosty scoring 1–5 w kluczowych wymiarach. Potem wybierz 2–3 najlepsze do programu pilotażowego.
A. Wartość biznesowa (Impact)
Oceń:
- ile godzin miesięcznie zjada proces,
- ile kosztują błędy (rework, reklamacje, straty),
- czy wpływa na przychód (konwersja, churn),
- czy odblokowuje skalowanie (więcej klientów bez zatrudniania).
Wskazówka: McKinsey zwraca uwagę, że „use case” powinien mieć mierzalny wynik (np. redukcja kosztu, wzrost przychodu).
B. Powtarzalność i standaryzacja
AI najlepiej usprawnia fragmenty, które są:
- częste,
- mają podobny wzór,
- mają jasne reguły brzegowe (kiedy eskalować).
C. Dane i dostęp (Data readiness)
Sprawdź:
- czy dane istnieją (ticketing/CRM/ERP/logi),
- czy są jakościowe (spójne pola, mało „wolnego tekstu” bez struktury),
- czy można ich użyć prawnie i bezpiecznie.
D. Integracje i wykonalność (Feasibility)
Pytania pomocnicze do oceny „trudności wdrożenia”:
- Ile systemów trzeba będzie zintegrować (i jak bardzo są od siebie zależne).
- Czy są dostępne API albo inne punkty integracji, czy wszystko będzie wymagało obejść.
- Czy da się działać „na boku” – np. zacząć w trybie asysty, shadow mode lub równoległego procesu, zanim wejdzie się „w główny nurt” operacji.
E. Ryzyko i kontrola (Risk)
Tu wchodzą w grę bezpieczeństwo, zgodność i reputacja. „Shadow AI” (używanie narzędzi AI bez nadzoru) jest realnym problemem – Gartner prognozuje, że do 2030 roku ponad 40% organizacji doświadczy incydentów bezpieczeństwa lub zgodności z tego powodu, więc polityki i edukacja są kluczowe.
Prosty sposób wyboru kandydata: najpierw celuj w procesy o wysokim Impact i wysokiej Feasibility, ale niskim Risk – to one powinny pójść na pierwszy ogień w pilocie.
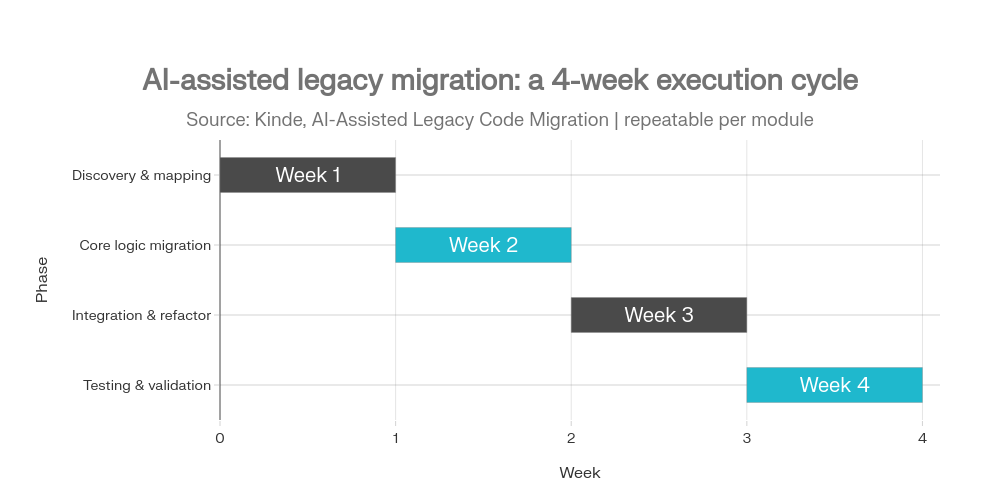
Krok 3: zdefiniuj „Thin slice” – minimalne wdrożenie, które dowozi KPI
Najczęstszy błąd: próbować usprawnić cały proces naraz.
Lepszy schemat:
- wybierz jeden etap procesu (np. „triage zgłoszeń”),
- ustal 1–2 KPI (np. czas pierwszej odpowiedzi, % poprawnych routingów),
- zbuduj rozwiązanie, które w 2–6 tygodni pokaże trend.
OpenAI w swoim przewodniku o identyfikacji i skalowaniu use case’ów podkreśla, że adopcja AI to więcej niż znalezienie pomysłu – potrzebujesz procesu, który prowadzi od wartości i leadershipu do wdrożenia i skali.
Krok 4: zaprojektuj kontrolę jakości i „bezpieczniki” od pierwszego dnia
Jeżeli AI ma wpływać na klienta, finanse albo bezpieczeństwo, ustaw jasne zasady: kto zatwierdza użycie, jakie dane wolno przetwarzać, jakie kontrole jakości obowiązują i jakie metryki ryzyka monitorujesz.
- human-in-the-loop (człowiek zatwierdza),
- progi ufności (poniżej progu → eskalacja),
- monitoring jakości (np. sampling 50 spraw tygodniowo),
- logowanie decyzji (audytowalność),
- politykę danych (co może wyjść do modelu / co nie).
To także realnie ogranicza ryzyko „shadow AI”, bo daje ludziom legalną, bezpieczną ścieżkę korzystania.
Krok 5: dopiero potem „skaluj” – standaryzuj i replikuj wzorzec
Skalowanie nie polega na „dokładaniu kolejnych promptów”. Polega na:
- standardzie integracji,
- bibliotece komponentów (np. klasyfikacja, ekstrakcja, generowanie, walidacja),
- wspólnych KPI,
- procesie wdrażania zmian i testów.
Dobrą praktyką jest proces discovery oparty o mining: process mining pokazuje, jak naprawdę płynie proces w systemach i gdzie powstają straty (wąskie gardła, zbędne kroki), a task mining ujawnia, jak ludzie wykonują pracę na desktopie i które czynności nadają się do automatyzacji.
Przykłady procesów, które AI zwykle usprawnia „naprawdę”
Poniżej inspiracje, które często dobrze przechodzą scoring:
Obsługa klienta / helpdesk
- klasyfikacja i routing ticketów,
- podsumowanie kontekstu z historii klienta,
- sugestia odpowiedzi + linki do bazy wiedzy,
- wykrywanie eskalacji/ryzyka churn.
Sprzedaż i marketing
- personalizowane szkice maili/ofert,
- streszczenia rozmów i uzupełnianie CRM,
- kwalifikacja leadów (asysta, nie „autopilot”).
Software engineering
- generowanie testów, dokumentacji, refactoring asystowany,
- triage błędów, podsumowania incydentów.
To koreluje z obszarami największej wartości wskazywanymi w analizie McKinsey.
FAQ: jak wybierać procesy, które AI naprawdę usprawni
Jak rozpoznać, że proces „nie nadaje się” na AI (jeszcze)?
Jeśli ma niski wolumen, duży chaos w danych, brak właściciela KPI albo bardzo wysokie ryzyko błędu bez możliwości kontroli – lepiej zacząć gdzie indziej lub najpierw uporządkować dane.
Czy AI powinno automatyzować proces end-to-end od razu?
Rzadko. Najczęściej lepszy start to asysta lub półautomaty z zatwierdzeniem człowieka, a dopiero potem zwiększanie autonomii, gdy masz dane o jakości.
Jakie dane są minimalnie potrzebne do sensownego pilota?
Wystarczy tyle, żeby mierzyć KPI i trenować/kalibrować rozwiązanie: logi procesu, historyczne zgłoszenia, opisy spraw, wyniki (np. czy routing był poprawny). Process mining / task mining mogą pomóc „wyciągnąć prawdę” o procesie z logów i działań użytkowników.
Jak uniknąć „shadow AI” i wycieku danych do narzędzi?
Daj zespołom bezpieczną alternatywę (zatwierdzone narzędzia, zasady danych, monitoring), a nie sam zakaz. Gartner ostrzega, że nieautoryzowane użycie AI może prowadzić do naruszeń bezpieczeństwa i zgodności.
Jak długo powinien trwać pilot, żeby miał sens?
Najczęściej 2–6 tygodni dla „thin slice”. Ważniejsze od czasu jest to, czy masz: KPI, właściciela, dostęp do danych i możliwość wdrożenia na realnym fragmencie pracy.
Czy process mining jest konieczny?
Nie zawsze, ale bardzo pomaga uniknąć decyzji na bazie opinii. Jeśli masz logi w systemach (CRM/ERP/ticketing), process mining szybciej pokaże wąskie gardła i warianty procesu.
Jakie KPI najczęściej pokazują realną wartość AI?
Czas realizacji (cycle time), czas pierwszej odpowiedzi, koszt obsługi sprawy, % błędów/reworku, satysfakcja klienta, przepustowość zespołu bez wzrostu zatrudnienia.