Secure SDLC w praktyce firmy tworzącej oprogramowanie: co wdrożyć najpierw?


Secure SDLC (czasem mówimy „DevSecOps”, „secure-by-design”) to nie jest pojedyncze narzędzie ani „projekt bezpieczeństwa”. To sposób wytwarzania i utrzymania software’u, w którym bezpieczeństwo jest wbudowane w codzienny przepływ pracy: od wymagań i projektu, przez kod i pipeline CI/CD, po obsługę podatności już po wydaniu.
Dla producenta oprogramowania (SaaS, on-prem, vendor, software wbudowane) kluczowe jest jedno: wdrożyć Secure SDLC tak, aby nie zabić tempa dostarczania, tylko je ustabilizować. Najlepiej działa podejście etapowe oparte na standardach i „małych, mierzalnych krokach”.
W tym artykule oprę kolejność działań o:
- NIST SSDF (SP 800-218) jako praktyczną listę obszarów „co musi być”, podzieloną na przygotowanie organizacji, ochronę artefaktów, wytwarzanie bezpiecznego software’u i reagowanie na podatności.
- Microsoft SDL jako sprawdzony zestaw praktyk (m.in. wymagania, threat modeling, secure coding, weryfikacja).
- OWASP ASVS jako punkt odniesienia do wymagań bezpieczeństwa aplikacji (co testować / co implementować).
- SLSA oraz SBOM jako fundament zabezpieczenia łańcucha dostaw (supply chain), coraz ważniejszego w wymaganiach klientów i regulacjach.
- Kontekst europejski: Cyber Resilience Act (CRA) podbija wagę procesów bezpieczeństwa u wytwórców, m.in. w obszarze obsługi podatności w cyklu życia.
Dlaczego „kolejność wdrożeń” jest ważniejsza niż lista narzędzi?
Wiele firm startuje od SAST/DAST i liczy, że skanery „zrobią Secure SDLC”. Efekt bywa odwrotny: rośnie liczba alertów, spada morale, a prawdziwe ryzyka (np. supply chain, brak procesu łatek, brak wymagań) zostają.
Bezpieczniejsza strategia to:
- najpierw ustawiasz zasady gry i przepływ odpowiedzialności,
- potem automatyzujesz kontrolę jakości (skany, testy),
- na końcu podnosisz dojrzałość (threat modeling na szeroko, twarde bramki release’owe, SLSA poziomami).
„Must have” Secure SDLC producenta (7 filarów)
Poniżej filary, które realnie robią różnicę u vendorów:
- Wymagania i standard: co znaczy „bezpieczne” w Twoim produkcie (np. ASVS poziom 1/2/3)
- Bezpieczny pipeline i artefakty: kontrola buildów, podpisy, provenance (SLSA)
- Zarządzanie zależnościami i SBOM: widoczność komponentów i szybka reakcja na CVE
- Bezpieczny projekt (threat modeling): wyłapywanie klas błędów zanim powstanie kod
- Bezpieczne kodowanie + code review: standardy, checklisty, szkolenia (SDL)
- Weryfikacja (SAST/DAST/IAST + testy bezpieczeństwa): automatyzacja i testy manualne tam, gdzie trzeba
- Vulnerability management & disclosure: proces, SLA na poprawki, komunikacja z klientami (ważne też regulacyjnie w UE)
Co wdrożyć najpierw? Priorytetyzacja „max efekt / min tarcie”
Priorytet 1: proces podatności i „kto odpowiada za co” (PSIRT + VDP)
To najczęściej największa luka u firm tworzących oprogramowanie: podatność wpada „gdzieś na support”, a potem ginie w mailach. Tymczasem CRA wymaga, żeby istniały jasne procedury obsługi zgłoszeń podatności i ich naprawy w całym cyklu życia produktu.
Co warto wdrożyć na start:
- Publiczny adres do zgłoszeń (np. security@twojadomena) oraz prostą politykę ujawniania podatności (VDP), żeby było wiadomo, jak zgłaszać problemy i czego może oczekiwać researcher.
- Proces triage: określenie krytyczności, wpływu i dotkniętych wersji, tak aby priorytety były spójne, a nie „na wyczucie”.
- SLA na reakcję i naprawę, np. Critical – 7 dni, High – 30 dni (dopasowane do Twojego biznesu i ryzyka).
- Uporządkowany proces wydawania poprawek oraz publikowania komunikatów bezpieczeństwa (security advisory), żeby klienci wiedzieli, co zrobić.
Dlaczego to punkt numer 1? Bo nawet najlepszy Secure SDLC nie pomoże, jeśli nie potrafisz szybko i przewidywalnie reagować na realne podatności, które już dziś dotykają Twojego produktu.
Priorytet 2: higiena dostępu i pipeline CI/CD (supply chain „quick wins”)
Ataki na łańcuch dostaw są dziś jednym z największych ryzyk. SLSA jest praktycznym „checklistem” w tym obszarze.
Wdrożenia od razu (bez przebudowy architektury):
- MFA wszędzie (repo, CI, chmura), zakaz współdzielonych kont,
- minimalne uprawnienia (least privilege) dla tokenów CI,
- tajemnice w secrets managerze, rotacja tokenów,
- ochrona branchy (wymagane review, status checks),
- build tylko z kontrolowanych runnerów, pinowanie wersji akcji/skryptów,
- rejestr artefaktów (artifact registry) + kontrola, co trafia na produkcję.
Efekt: mniejsze ryzyko, że ktoś przejmie pipeline i w ramach ataku na łańcuch dostaw wypchnie złośliwy build na produkcję.
Priorytet 3: dependency management + SBOM (widoczność = szybkość reakcji)
SBOM to formalna lista komponentów Twojego software’u. NTIA definiuje minimum elementów SBOM, a CISA utrzymuje materiały i aktualizacje dot. SBOM.
Jeśli nie wiesz, co masz w zależnościach, nie odpowiesz klientowi na pytanie: „czy jesteście podatni na X?”.
Co warto wdrożyć na start:
- automatyczne skanowanie zależności (SCA) w CI,
- generowanie SBOM (np. CycloneDX lub SPDX) jako artefakt builda
- proces „nowe CVE”: identyfikacja dotkniętych wersji → decyzja → patch → komunikat.
To ogromny boost zaufania u klientów B2B – pokazujesz, że traktujesz bezpieczeństwo i obsługę podatności jako element produktu, a nie „koszt uboczny”
Priorytet 4: „wymagania bezpieczeństwa” jako standard jakości (ASVS / SDL)
W praktyce Secure SDLC działa wtedy, kiedy dev wie co ma być spełnione, a QA/CI potrafi to sprawdzić.
OWASP ASVS daje gotową listę wymagań dla aplikacji webowych (i usług), a Microsoft SDL pokazuje, jak wpleść praktyki security w cykl wytwarzania.
Jak zacząć lekko:
- wybierz poziom ASVS (często start: Level 1 dla baseline),
- wyciągnij z niego 10–20 wymagań „najbardziej bolesnych” (auth, sesje, logowanie, walidacje),
- zrób z tego checklistę DoD (Definition of Done) dla feature’ów.
Priorytet 5: threat modeling w punktach krytycznych (nie wszędzie naraz)
Threat modeling to rdzeń SDL i świetne narzędzie do redukcji kosztu błędów projektowych.
W praktyce producenta:
- zacznij od 2–3 „user journeys” o najwyższym ryzyku: logowanie, reset hasła, płatności, integracje API,
- rób krótkie sesje (60-90 min): aktorzy, aktywa, granice zaufania, scenariusze nadużyć,
- wynik ma być „lista decyzji i zabezpieczeń”, nie dokument dla dokumentu.
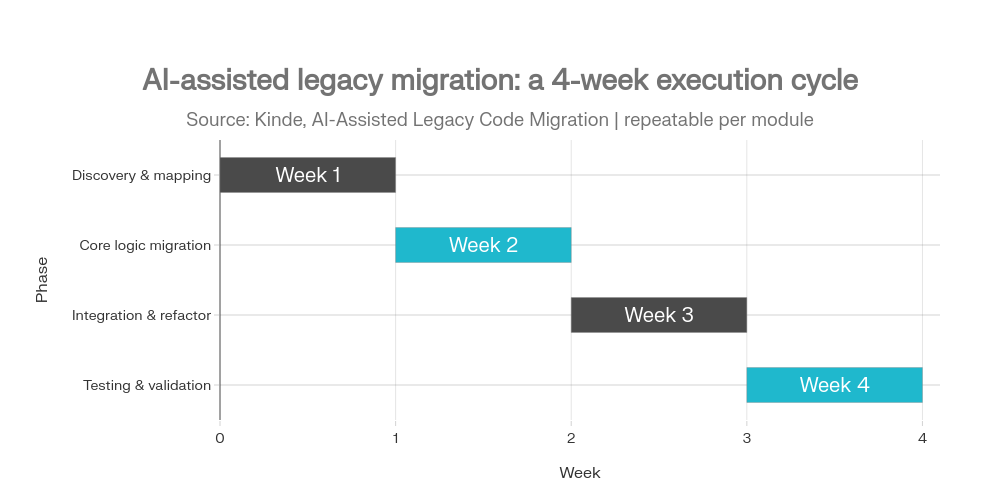
Roadmapa wdrożenia: 30 / 90 / 180 dni (realistycznie)
Pierwsze 30 dni: fundamenty, które natychmiast obniżają ryzyko
- PSIRT/VDP + prosty proces podatności (triage, SLA, advisory).
- MFA, ochrona repo i CI, porządek w secretach.
- Dependency scanning + podstawowy SBOM jako artefakt builda.
- Minimum standardu wymagań (np. ASVS Level 1 jako „baseline”).
KPI na koniec 30 dni: czas odpowiedzi na zgłoszenie podatności, % projektów ze skanem zależności i SBOM, % pipeline’ów z MFA/ochroną.
90 dni: automatyzacja jakości i bramki bezpieczeństwa „bez dramatu”
- SAST w CI + zasady triage (co blokuje, co jest backlogiem).
- DAST dla najważniejszych endpointów / środowiska staging.
- Threat modeling dla top 2–3 ścieżek krytycznych.
- Standard secure coding (checklista) i wymagane review dla obszarów bezpieczeństwa (auth, uprawnienia).
- Pierwsze elementy SLSA: kontrola buildów i provenance tam, gdzie możliwe.
KPI na koniec 90 dni: trend podatności krytycznych, pokrycie skanami, czas naprawy (MTTR) dla high/critical.
180 dni: dojrzałość producenta (compliance-ready + skalowalność procesu)
- SLSA poziomami (wzrost wymagań na build i artefakty)
- SBOM + proces aktualizacji + integracja z vulnerability intel (szybkie odpowiedzi klientom).
- Program redukcji „klas podatności” (np. injection, SSRF, auth bypass) – zgodnie z podejściem Secure by Design promowanym przez CISA (dla vendorów).
- Regularne testy penetracyjne / red teaming dla krytycznych modułów.
- „Security champions” w zespołach produktowych (żeby skalować praktyki).
Jak to wdrożyć, żeby dev nie znienawidził Secure SDLC?
Zasada 1: nie wszystko „blokuje release”
Ustal politykę:
- co blokuje (np. critical w zależnościach w komponencie internet-facing),
- co wymaga planu (high),
- co może być backlogiem (medium/low).
Bez tego Secure SDLC zamienia się w „fabrykę alertów”.
Zasada 2: triage jest ważniejszy niż liczba narzędzi
NIST SSDF wprost traktuje to jako praktykę organizacyjną: przygotuj organizację, chroń oprogramowanie, produkuj dobrze zabezpieczone oprogramowanie, reaguj na podatności. W narzędziach można utonąć, ale to właśnie dobry triage i sensowne SLA robią różnicę – to ta „mechanika”, która realnie dowozi proces reagowania na podatności.
Zasada 3: security requirements muszą być „testowalne”
ASVS pomaga, bo jego wymagania da się wprost zmapować na konkretne testy i kontrolki bezpieczeństwa, dzięki czemu nie zostają tylko „na papierze”, ale przekładają się na praktykę.
Minimalny zestaw „policy / dokumentów”, które naprawdę mają sens
- Secure SDLC Policy (1–2 strony): zakres, odpowiedzialności, bramki.
- VDP / polityka zgłaszania podatności + kontakt.
- Standard zależności: kto zatwierdza nowe biblioteki, jak reagować na CVE.
- Secure coding checklist (krótka, praktyczna).
- Release security checklist (SBOM, skany, podpisy, rollback plan).
Najczęstsze błędy producentów (i antidota)
- Start od DAST na produkcji → zacznij od pipeline, SBOM i procesu podatności (mniej chaosu).
- Brak właściciela podatności → powołaj PSIRT (nawet 2 osoby) i ustal SLA.
- „Włączamy SAST i zobaczymy” → bez triage i reguł blokowania zatrzymasz development.
- SBOM jako PDF raz na kwartał → SBOM ma być artefaktem builda (powtarzalnym i aktualnym).
Najlepsza kolejność wdrożeń
- Vulnerability handling (PSIRT + VDP + SLA)
- Higiena dostępu + zabezpieczenie CI/CD
- SCA + SBOM + proces reakcji na CVE
- Standard wymagań (ASVS jako baseline) + DoD
- Threat modeling dla krytycznych ścieżek (SDL)
- SAST/DAST z regułami triage i sensownymi bramkami
- SLSA poziomami + twardnienie łańcucha dostaw
FAQ - Secure SDLC w praktyce producenta oprogramowania
Czym Secure SDLC różni się od DevSecOps?
Secure SDLC to pełny zestaw praktyk bezpieczeństwa w całym cyklu życia (wymagania → projekt → kod → testy → release → utrzymanie i podatności). DevSecOps zwykle akcentuje automatyzację i wbudowanie security w pipeline i operacje. W praktyce DevSecOps jest „jak to robimy”, a Secure SDLC „co musi być robione” (w sensie standardu i governance). NIST SSDF dobrze to porządkuje na obszary praktyk.
Od czego zacząć Secure SDLC, jeśli mamy mały zespół i mało czasu?
Największy efekt przy najmniejszym tarciu daje:
- proces obsługi podatności (VDP/PSIRT + SLA),
- MFA + porządek w dostępach i secretach w CI/CD,
SCA + SBOM jako artefakt builda. To buduje gotowość na realne incydenty i pytania klientów „czy jesteście podatni na X?”.
Czy SAST/DAST powinny blokować release?
Nie od razu. Sensowniejsze jest podejście „progressive hardening”:
- na start: widoczność + triage (bez twardej bramki),
- potem: blokowanie tylko krytycznych (np. RCE, auth bypass) w komponentach wystawionych do internetu,
docelowo: twarde bramki dla ustalonego profilu ryzyka. W przeciwnym razie Secure SDLC zamienia się w „fabrykę alertów” i zabija tempo.
Jak ustalić „wymagania bezpieczeństwa” dla produktu, żeby to miało sens?
Najprościej: przyjąć OWASP ASVS jako baseline (często Level 1 na start), wybrać 10–20 wymagań kluczowych (auth, sesje, logowanie, walidacje, uprawnienia), a następnie:
- dopiąć je do Definition of Done,
- przypisać do testów (automatycznych tam, gdzie się da),
włączać kolejne wymagania iteracyjnie.
Czy threat modeling jest obowiązkowy i czy nie jest „za ciężki”?
Nie musisz robić threat modelingu dla wszystkiego. Najlepsza praktyka to zacząć od 2–3 krytycznych ścieżek (logowanie, reset hasła, płatności, integracje API). Krótkie sesje (60–90 min) potrafią usunąć klasy ryzyk, które potem trudno wykryć skanerami. Microsoft SDL traktuje to jako ważny element procesu.
Co to jest SBOM i czy klienci naprawdę tego oczekują?
SBOM (Software Bill of Materials) to lista komponentów (zależności, wersje, dostawcy), z których składa się Twój produkt. Coraz częściej jest to wymóg w przetargach i u klientów enterprise, bo umożliwia szybkie sprawdzenie wpływu nowych CVE. NTIA opisuje minimalny zestaw elementów SBOM.
Jak szybko reagować na nowe CVE w zależnościach?
Dobre minimum procesu:
- automatyczny alert (SCA / advisories),
- identyfikacja dotkniętych wersji (SBOM),
- decyzja: patch / workaround / brak wpływu,
- release poprawki + komunikat bezpieczeństwa,
mierzenie MTTR podatności. To część „producentowskiej” dojrzałości i mocno skraca chaos przy głośnych CVE.
Jak ograniczyć ryzyko supply chain (podmiana builda, złośliwe dependency)?
Najpierw higiena:
- MFA, least privilege, kontrolowane runner’y CI,
- podpisywanie artefaktów, kontrola pochodzenia (provenance). SLSA jest dobrym drogowskazem, bo daje stopnie dojrzałości i konkretne wymagania.